 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeField typing for improved recognition on heterogeneous handwritten forms
Sep 23, 2019
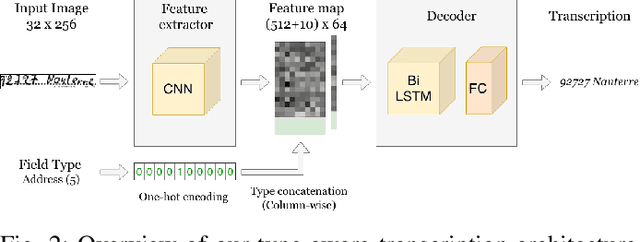


Offline handwriting recognition has undergone continuous progress over the past decades. However, existing methods are typically benchmarked on free-form text datasets that are biased towards good-quality images and handwriting styles, and homogeneous content. In this paper, we show that state-of-the-art algorithms, employing long short-term memory (LSTM) layers, do not readily generalize to real-world structured documents, such as forms, due to their highly heterogeneous and out-of-vocabulary content, and to the inherent ambiguities of this content. To address this, we propose to leverage the content type within an LSTM-based architecture. Furthermore, we introduce a procedure to generate synthetic data to train this architecture without requiring expensive manual annotations. We demonstrate the effectiveness of our approach at transcribing text on a challenging, real-world dataset of European Accident Statements.